




Introduction to Second Preimage Attacks
Building a Simple Merkle Tree
Consider we have an array ["L1", "L2", "L3", "L4"] just to keep the Merkle tree simple. Considering we will be using keccak256 hashing, each of these values will be hashed before being used as a leaf. So the leaves for the tree will look like the following:
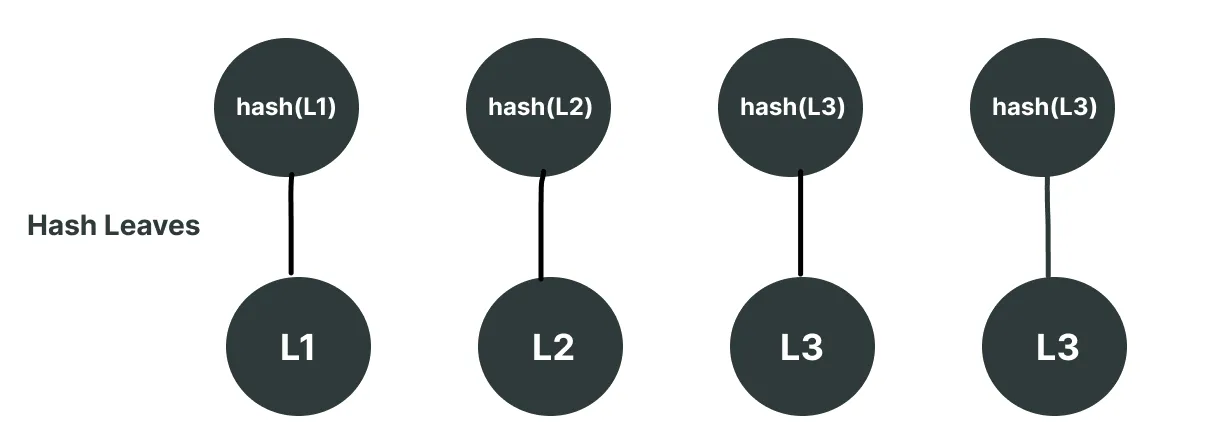
Next, we will hash together the concatenation of these hashes, step by step building up the tree.
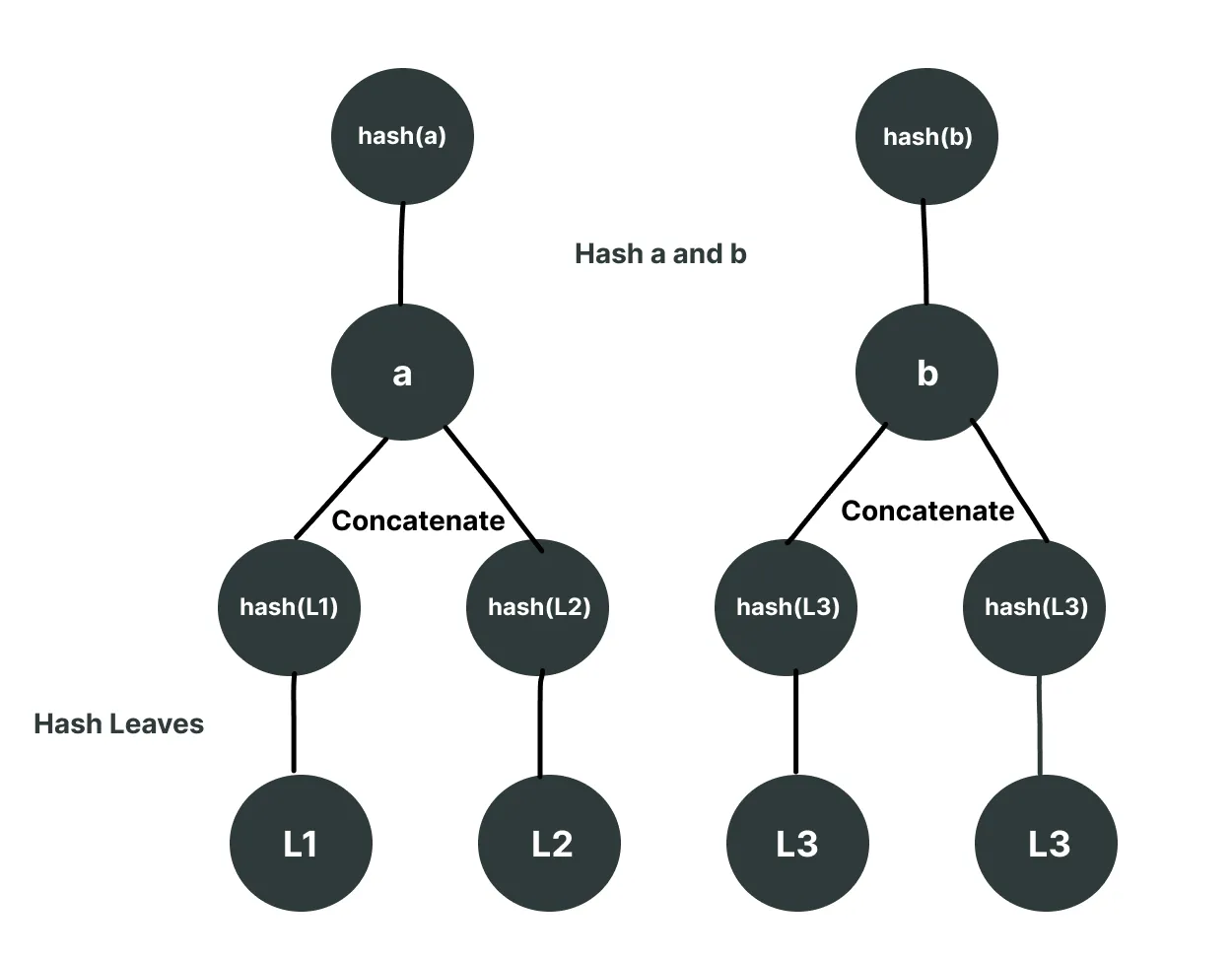
Next, we will concatenate together these last two nodes and hash them to get the root, and voila, we have a complete Merkle tree.
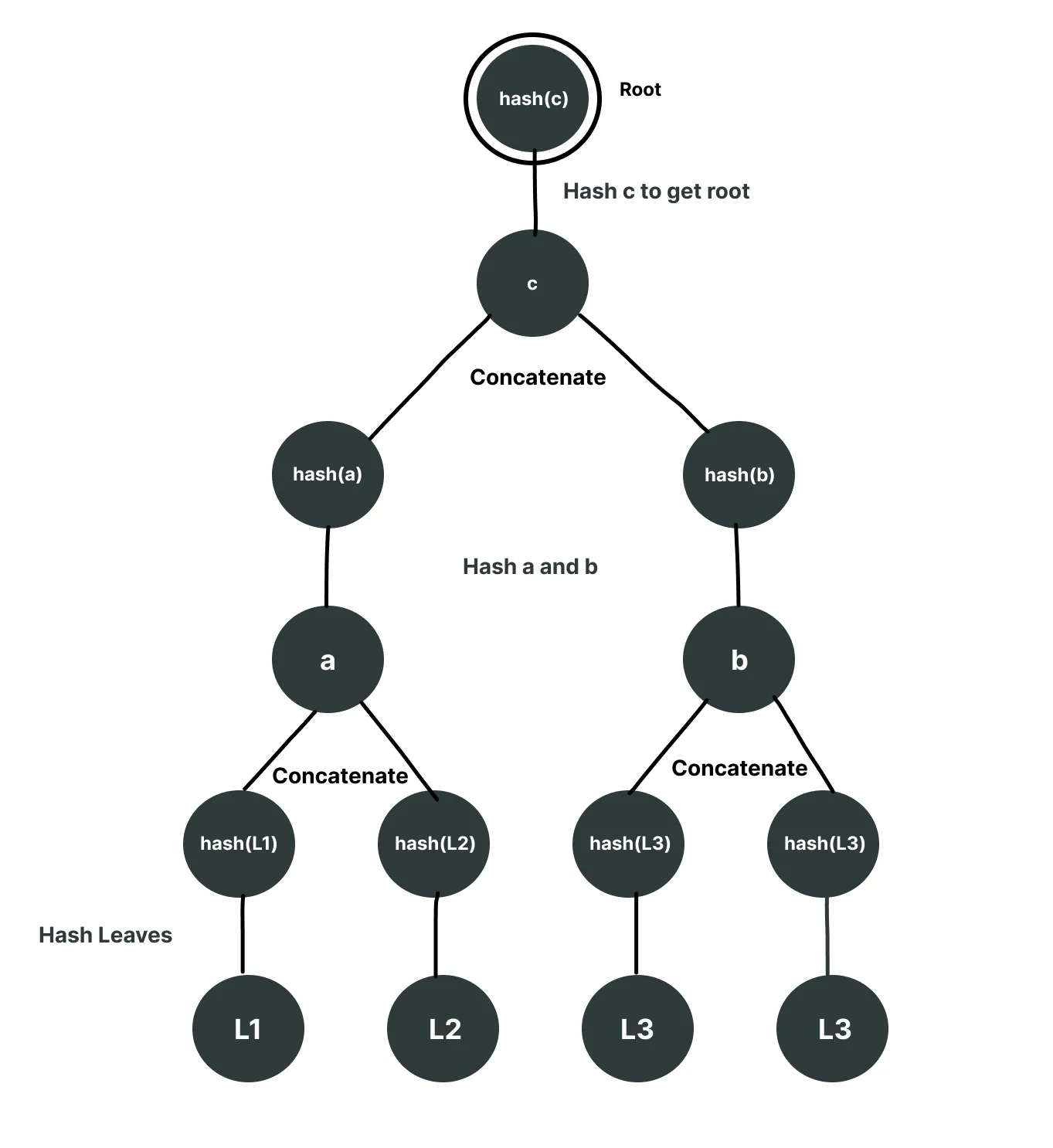
Understanding the Attack: How Second Preimage Exploits Work
A verify function for a Merkle proof takes two things: one is the unhashed leaf (considering the leaf whose existence we want to prove is L1), and an array of proof that has the intermediary nodes to form the root using the leaf. It then hashes the leaf first and then constructs the root. If the root derived from the proof and L1, matches the stored root, verification passes. Notably, the proof length is only log₂(number of leaves), making it remarkably compact - for example, proving membership in a tree with 1 million leaves requires just 20 hashes, which is why Merkle trees are so efficient for large datasets.
The function signature for a verify function in rust would look like following:
fn verify(leaf: &[u8], proof: &[[u8; 32]]) -> bool
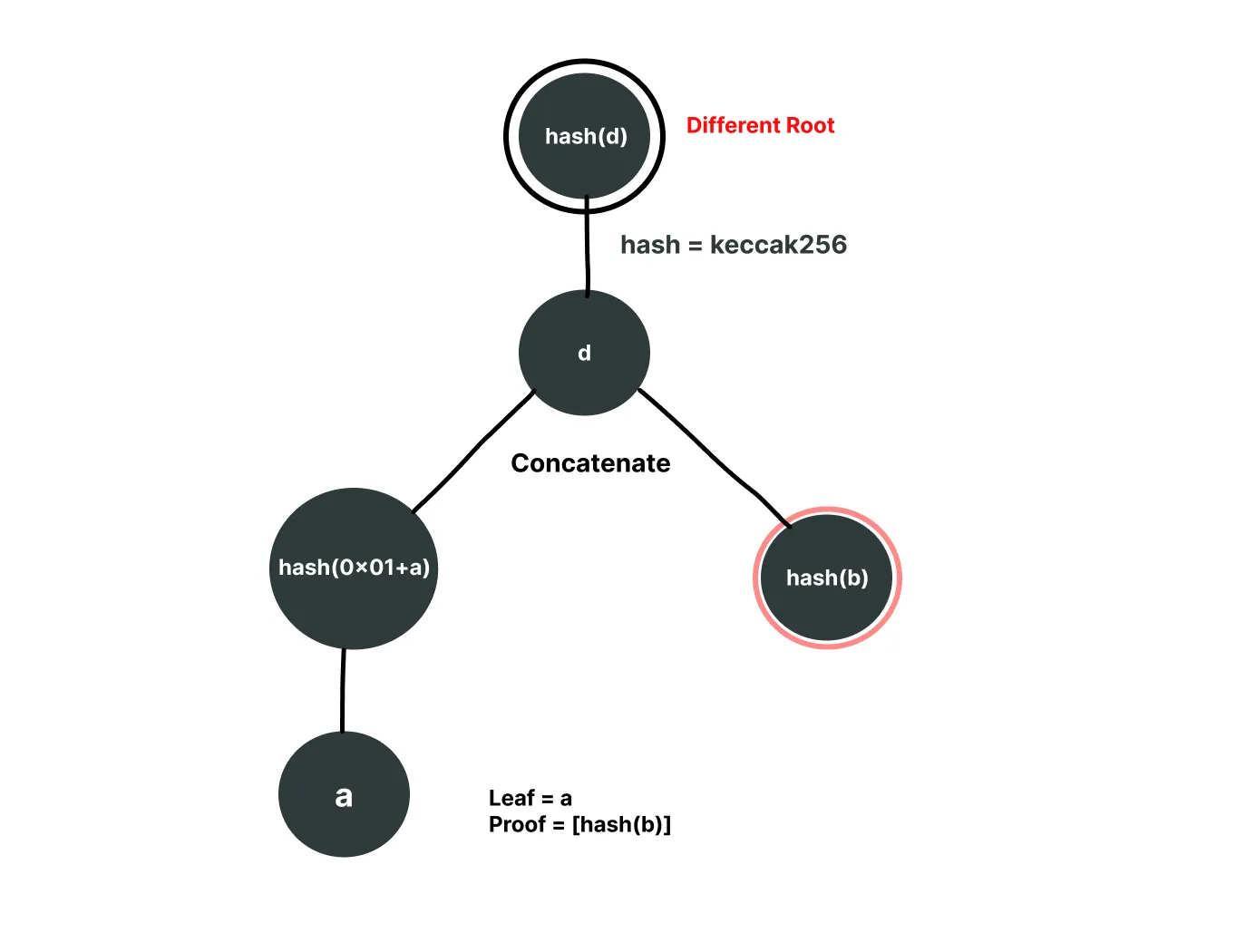
To prove L1, we will need the following nodes from the tree: [hash(L2), hash(b)] marked red.
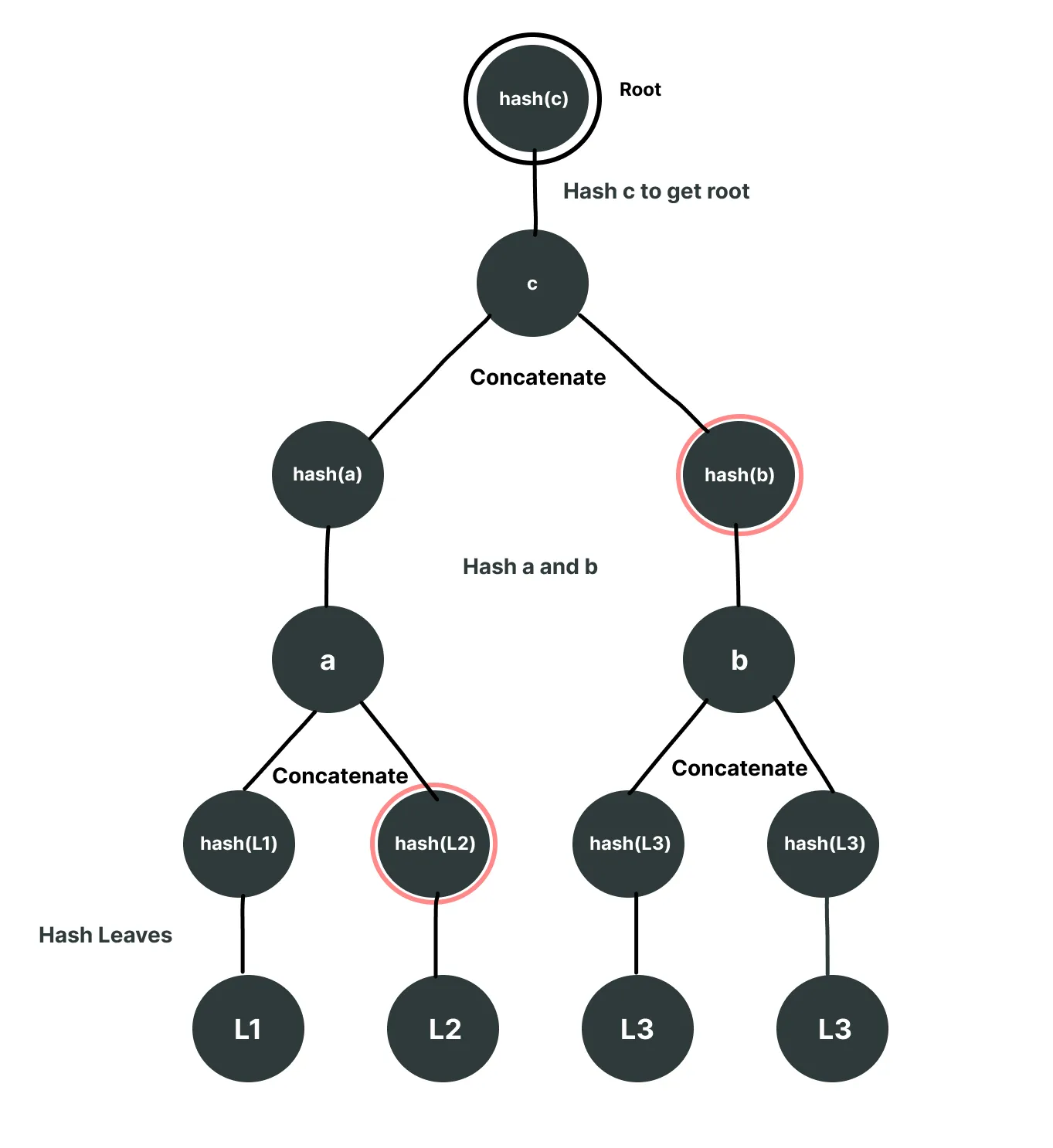
The path to generating the root from the given leaf and proof nodes will look like following
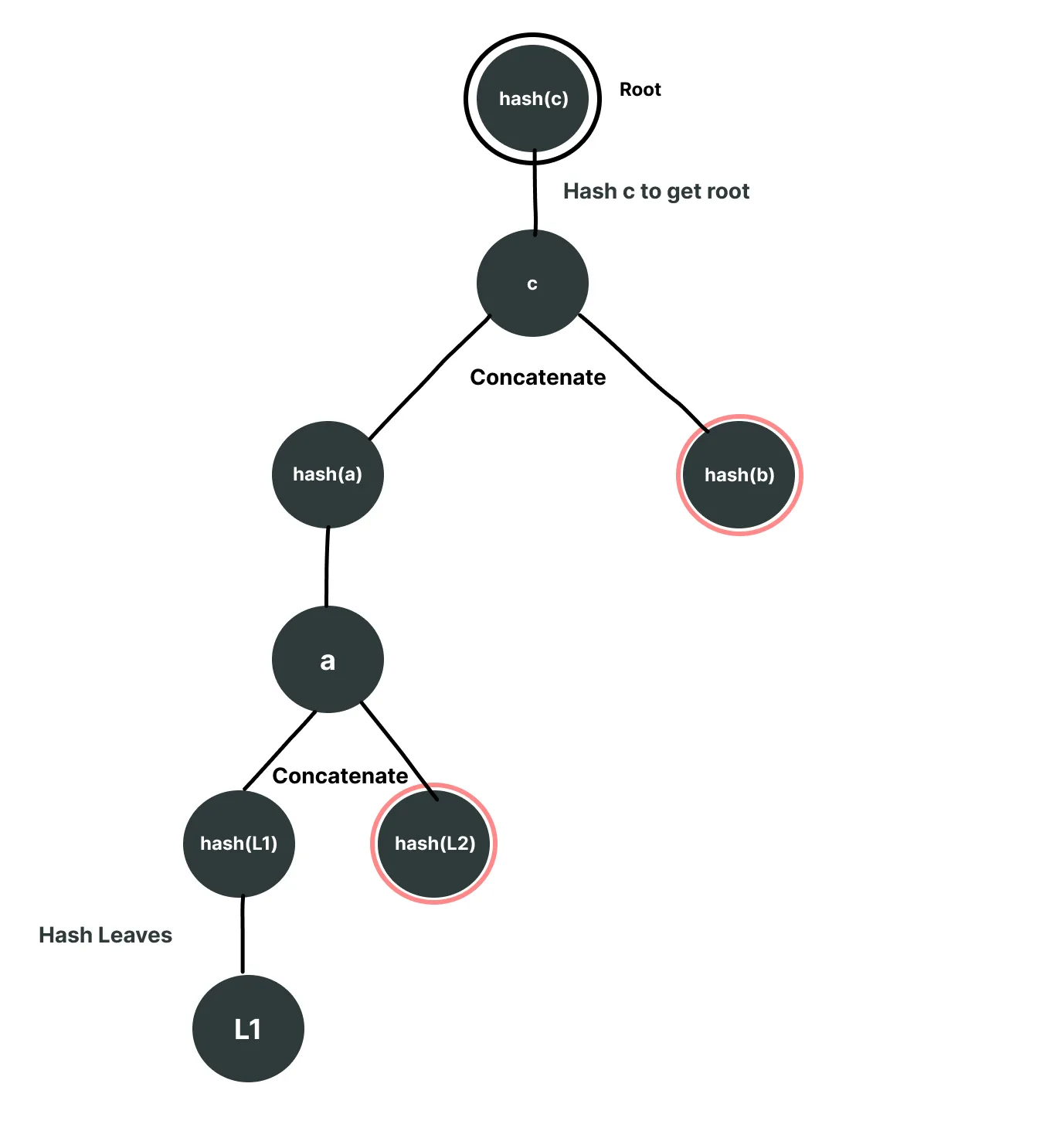
Now think about how we can prove a leaf that doesn't even exist in this Merkle tree. What if we provide a as the leaf (where a is the concatenation of hash(L1) and hash(L2)) and provide [hash(b)] as the proof array? The verification will first hash a to get hash(a), then concatenate it with hash(b) and hash again to get the same root. This succeeds even though a never existed as a leaf,it's actually an intermediary node.
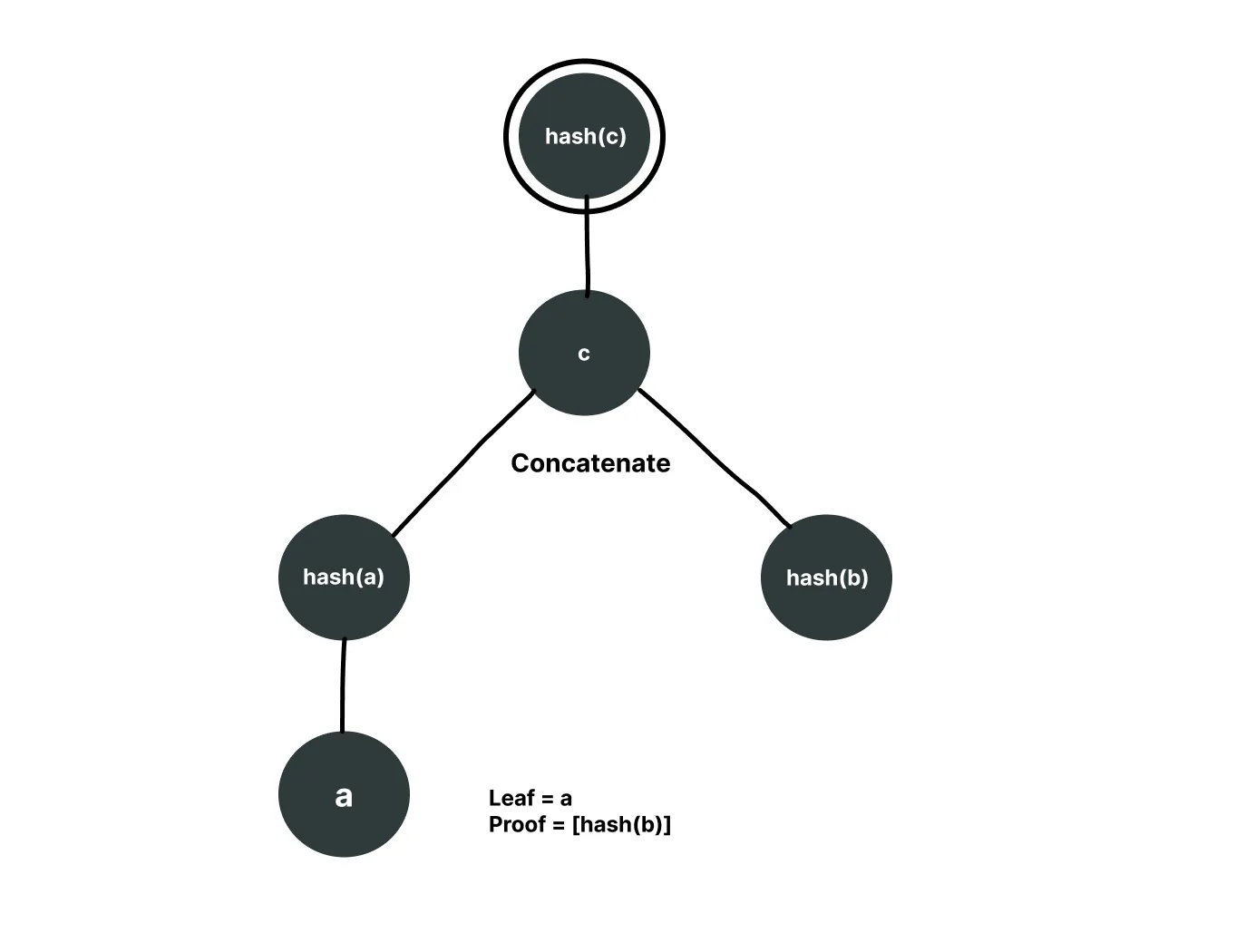
We were able to get the same root for a leaf that doesn't even exist.
Defense Strategies: Four Ways to Prevent Second Preimage Attacks
1. Separate Hash Functions for Leaves and Nodes
Consider we use Keccak256 for hashing the nodes and SHA256 for hashing the leaves. Let's see what will happen in that case. Taking the same example from above where:
leaf = a -> concatenation of hash of L1 and hash of L2
proof = [hash(b)] -> hash of concatenation of hash(L3) and hash(L4)
Now since a is provided as a leaf, instead of using Keccak256 for its hashing in the original tree, the verify function will try to hash it using SHA256, resulting in a completely different root. Hence, the second preimage attack will fail.

2. Double Hashing Leaf Nodes
This is similar to the first solution. The only difference is instead of using a different hash, we hash the leaves twice and the inner nodes once. Let's say we are using the Keccak256 hash. The tree will look like the following:
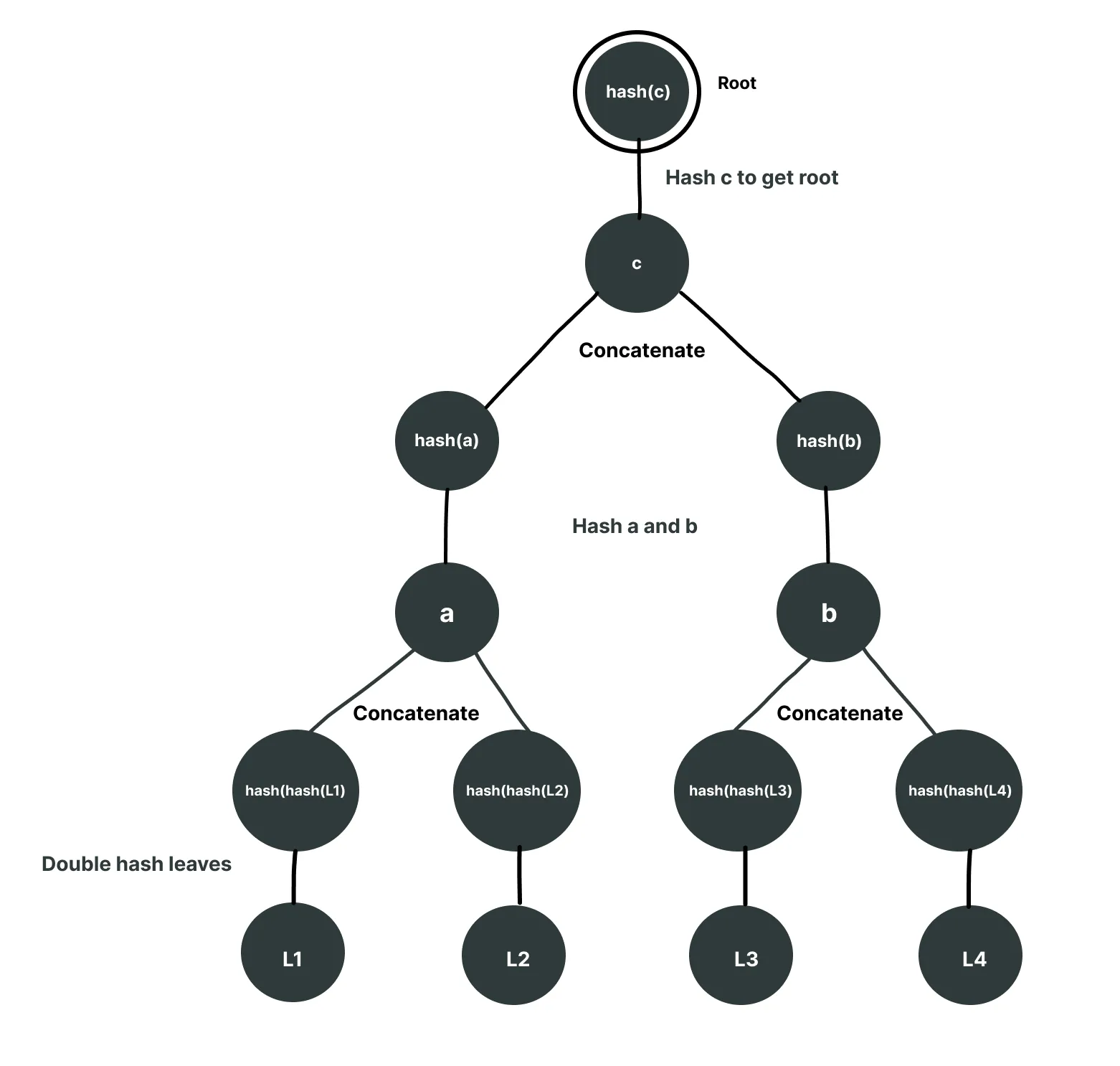
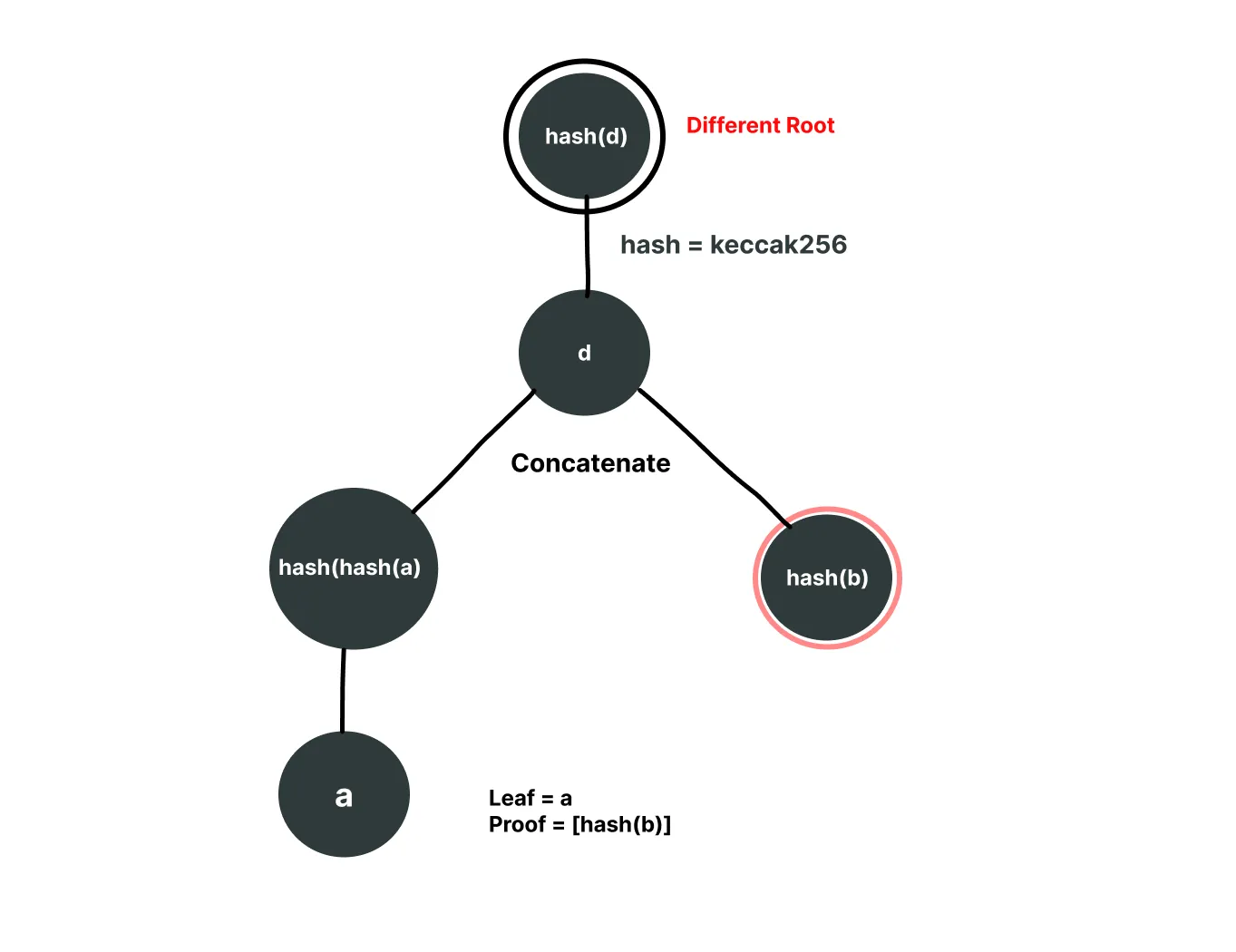
Now if we try to input a as a fake leaf, the verifier will hash it twice, hence resulting in a different root and a different hash.
3. Adding Prefixes to Separate Leaf and Node Hashes
In this case the hash will remain the same and there will be no double hashing either, but before hashing we will add some prefix. It will be different for the leaves and nodes. For example:
Leaf Prefix = "0x01"
Node Prefix = "0x02"
The tree will look like the following:
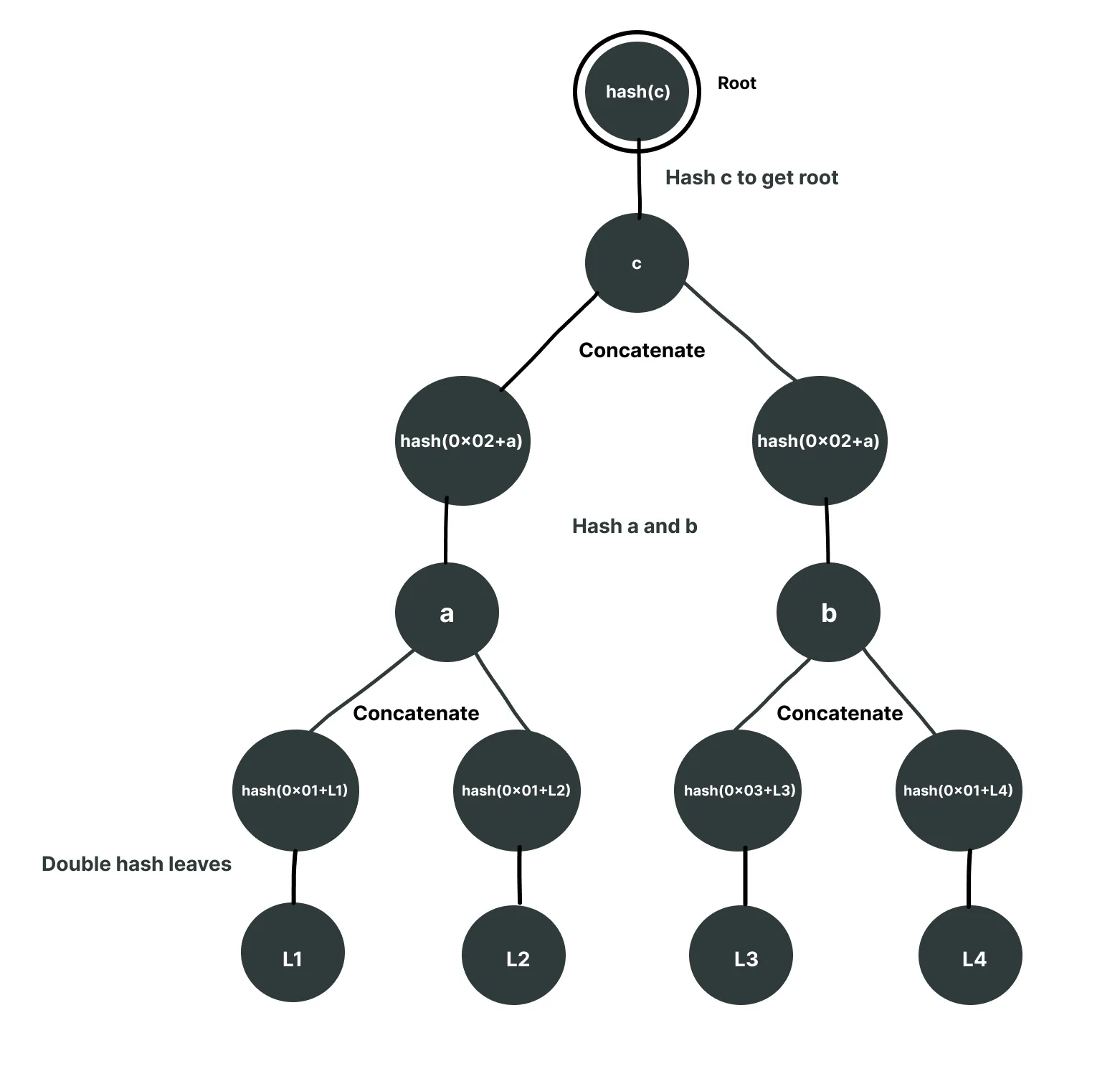
And given a as a leaf, it will hash it with prefix 0x01 instead of 0x02, resulting in a different leaf.
4. Using Byte-Length Restrictions for Leaves
This is how OpenZeppelin prevents this attack in the Merkle tree library. Considering the hashes in Solidity are 32 bytes, concatenating two 32-byte hashes at each level results in 64 bytes, and then these 64 bytes are hashed back to 32 bytes. So if we restrict that the leaf can only be 32 bytes before hashing, we can prevent this attack. Here is how: Consider a tree that only accepts 32 bytes as a leaf. Now if an attacker tries to provide a (which is the concatenation of hash(L1) and hash(L2), totaling 64 bytes) as a leaf, it will be rejected since it exceeds the 32-byte limit, thus preventing the attack.
Conclusion
The second preimage attack exploits the lack of distinction between leaf and internal node hashes in Merkle trees, allowing attackers to forge proofs for non-existent data. Fortunately, multiple effective mitigations exist: using different hash functions, double hashing leaves, adding prefixes, or restricting leaf sizes. All these approaches share the same core principle: ensuring that internal nodes cannot be disguised as leaves to produce the same root.
When implementing Merkle trees in production, it's important to understand that not all prevention techniques can be meaningfully combined. Here's a comparison:
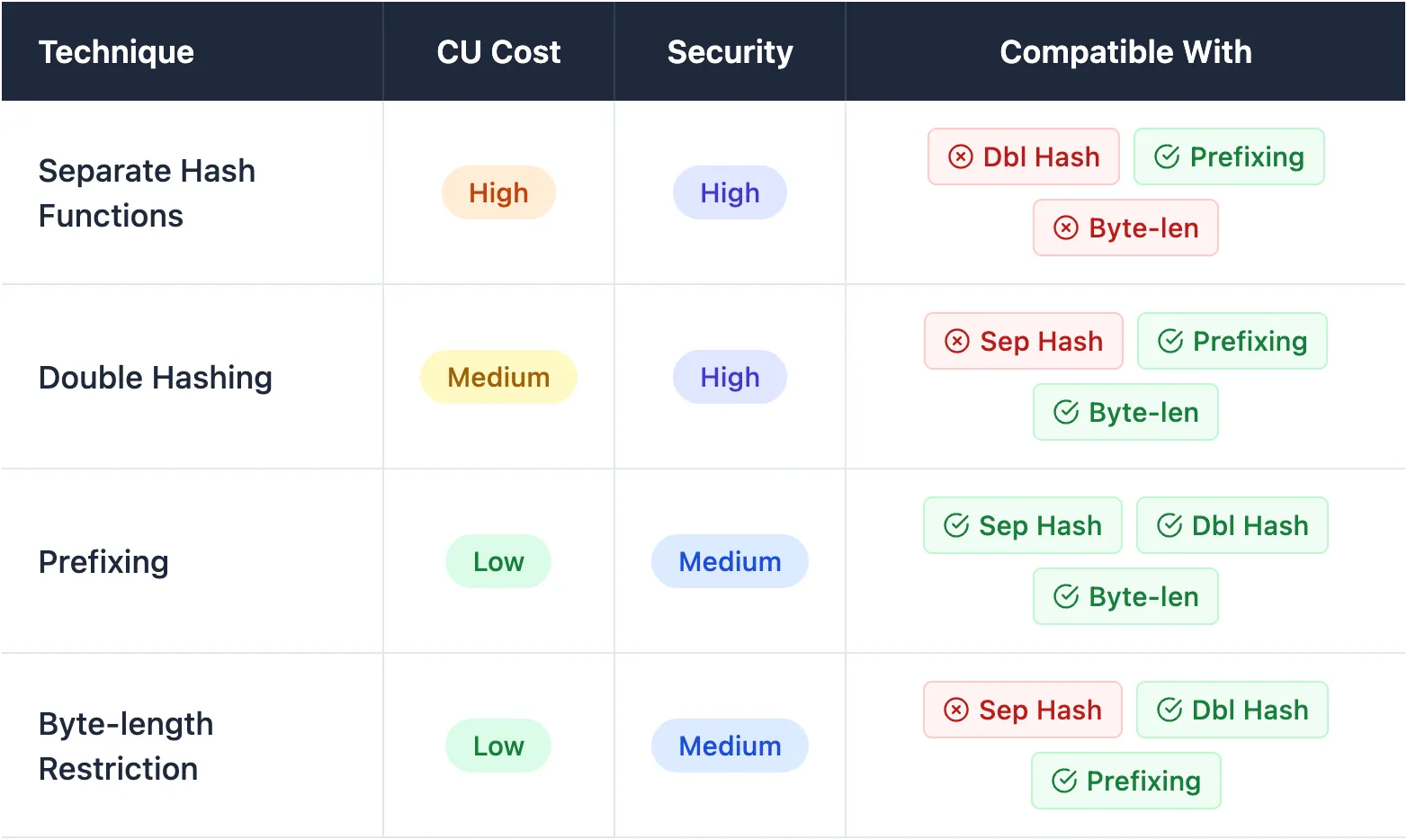
The key insight is that combining two techniques that fundamentally change how hashing works (separate hash functions + double hashing) is redundant and wasteful, while prefixing is universally compatible since it simply adds metadata without changing the hashing mechanism itself.
We will continue publishing practical, high-signal deep dives builders and auditors working close to the metal. Follow Adevar Labs on X and LinkedIn to stay updated.

